
Can Mistral LLM win at Poker? - Mistral Fine-tuning Hackathon
In this post, I will walk you through the exciting project I undertook with Anatole Vakili and Julien Delavande during the 2024 Mistral AI Fine-Tuning Hackathon.
Context
Recent research has demonstrated that fine-tuning large language models (LLMs) on standardized formats, such as PGN for chess games, leads to remarkable results:
- The LLM learns to play exclusively valid moves without being explicitly taught the rules.
- The model adapts its playing style based on the opponent’s behavior and considers the entire history of previous moves when making decisions.
- The fine-tuned LLM achieves an impressive ELO rating of 1800, significantly outperforming non fine-tuned models.
While these results are impressive in chess, we wondered if LLMs could perform just as well in other games, particularly Poker. Poker presents unique challenges compared to chess—it’s a multiplayer game with hidden information, and outcomes are not deterministic. Additionally, psychological factors play a significant role in decision-making. Furthermore, it’s difficult to build AIs that are good at Poker; the only approaches that seem to stand out use Reinforcement Learning.This led us to explore a compelling question: Can an LLM learn to play poker effectively?
The goal was to fine-tune the Mistral 7B model to become an intelligent poker bot, capable of making in-game decisions such as betting, calling, folding, or raising based on historical poker data.
Data Preparation
Our approach involved truncating poker hands at various stages of the game and prompting the LLM to predict the next action. We applied this strategy across a wide range of scenarios:
The model was tasked with making decisions from different positions at the table, whether early, middle, or late. We also ensured that the model experienced a variety of combinations and strengths. The truncation was applied at different phases of the game, such as pre-flop, post-flop, turn, and river, forcing the model to learn to play at the different stages of hands.
The dataset consisted of a professional player’s game history, representing different gameplay situations, which helped the model to develop a robust understanding of the dynamics of the game.
This is an example of prompt where the LLM is ask to play first post-flop:
Seat 7 is the button
Seat 1: BIGRAISE (174.47).
Seat 3: cracypoker (231.55).
Seat 5: bjv1105 (522.98).
Seat 6: IlxxxlI (80).
Seat 7: WalterBlack (125).
Player TheFront7 has small blind (2)
Player BIGRAISE has big blind (4)
Player BIGRAISE received a card.
Player BIGRAISE received a card.
Player cracypoker received a card.
Player cracypoker received a card.
Player bjv1105 received a card.
Player bjv1105 received a card.
Player IlxxxlI received card: [Qc]
Player IlxxxlI received card: [Jh]
Player WalterBlack received a card.
Player WalterBlack received a card.
Player cracypoker folds
Player bjv1105 folds
Player IlxxxlI calls (4)
Player WalterBlack calls (4)
Player BIGRAISE checks
*** FLOP ***: [10s Ac Ad]
Player IlxxxlI
Evaluation and results
Model Evaluation
To evaluate the fine-tuned LLM, we computed several metrics on a test set. These metrics allow us to assess whether the LLM is effectively mimicking the actions of the professional players it has learned from.
Metrics:
-
Ratio of Legal Moves:
Ratio of Legal Moves = Number of Legal Moves / Number of Moves Played
Illegal moves include actions such as “check” instead of “call” after a raise. This metric evaluates the LLM’s ability to deduce and follow the rules of the game. -
Accuracy:
Accuracy = Number of Moves Matching the Professional Player / Number of Moves Played
This measures the model’s ability to replicate the decision-making of a professional player.
As a baseline for comparison, we prompted ChatGPT 3.5 (non-fine-tuned) to play on the same test set. The prompt was adapted to clarify the task and instruct it to predict the next moves.
Results obtained from the Mistral fine tuned model (MistralBluff) on the testset:
| bets | calls | raises | allin | checks | folds | caps | |
|---|---|---|---|---|---|---|---|
| bets | 16 | 0 | 0 | 0 | 20 | 0 | 0 |
| calls | 0 | 38 | 5 | 0 | 0 | 59 | 0 |
| raises | 0 | 4 | 45 | 0 | 0 | 46 | 0 |
| allin | 0 | 0 | 0 | 2 | 1 | 6 | 0 |
| checks | 8 | 0 | 1 | 0 | 151 | 0 | 0 |
| folds | 0 | 19 | 15 | 0 | 0 | 3017 | 0 |
| caps | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
Results obtained from a non fine tune ChatGPT 3.5 on the testset:
| bets | calls | raises | allin | checks | folds | caps | |
|---|---|---|---|---|---|---|---|
| bets | 14 | 0 | 0 | 0 | 8 | 0 | 0 |
| calls | 0 | 16 | 5 | 0 | 0 | 0 | 0 |
| raises | 0 | 3 | 45 | 0 | 0 | 0 | 0 |
| allin | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| checks | 36 | 0 | 1 | 0 | 44 | 0 | 0 |
| folds | 7 | 87 | 15 | 0 | 48 | 1 | 0 |
| caps | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
MistralBluff achieved an accuracy of 94.5%, compared with 3.5% for ChatGPT. This is because the non-fine-tuned model hardly folds at all, whereas statistically, it’s better to fold the majority of poker hands.
Another interesting statistic is that MistralBluff has 100% legal moves versus only 12.5% for ChatGPT.
These results show that fine tuning has proved effective and that MistralBluff has indeed learned to play poker.
Poker Ranges: Understanding Play Styles
Poker ranges provide a valuable insight into a player’s strategy by illustrating their decision-making. Essentially, a range is a visual representation of the actions a player is likely to take with different hands depending on their position at the table.
Skilled players tend to have a wider opening range the later they play in a round. This means they are more likely to make aggressive moves with a broader selection of hands. Additionally, players often favor suited hands over off-suited ones when deciding which hands to play aggressively.
Let’s compare the opening ranges of Mistral Bluff to those of a professional poker player to better understand how the model performs in various positions at the table.
Opening ranges in early positions
The Under the Gun (UTG) position is considered an early position in poker, where players must be more selective with their hands. Let’s examine the opening range of a professional player in this position:
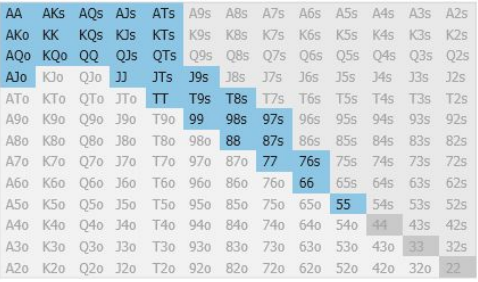
Here is the raise rate for MistralBluff in the same scenario:
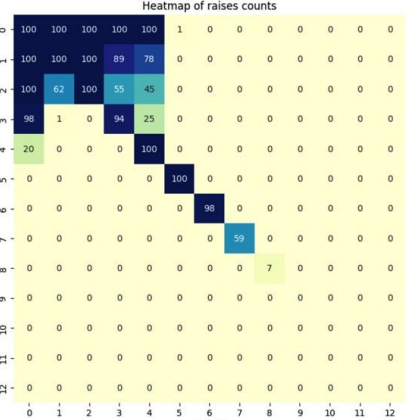
Both ranges are remarkably similar, indicating that MistralBluff has a good understanding of poker.
Opening ranges in late positions
Next, let’s explore the ranges from the Big Blind (BB) position, which is typically the last to act in a round.
Typical Opening Range of a Professional Player:
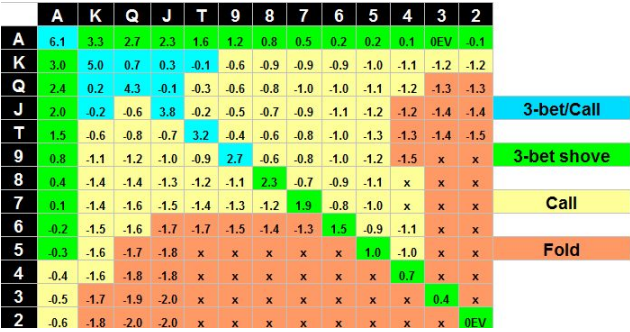
Now, here’s the fold rate for MistralBluff in this position:
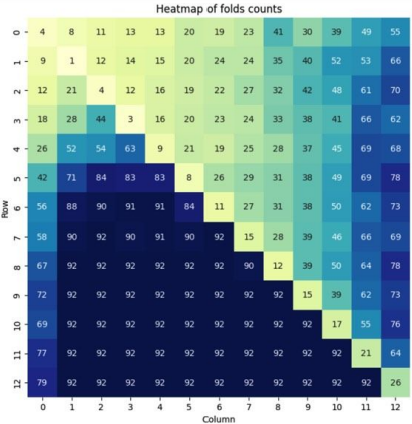
This comparison highlights that MistralBluff recognizes the importance of table position when determining opening ranges. Furthermore, it shows an awareness that suited hands have more value. Overall, MistralBluff’s style closely mirrors that of professional players, demonstrating its capability to adapt to the dynamics of the game.
Critiques and Perspectives
Despite promising results, there are several areas for improvement:
-
Sizing: MistralBluff struggles with raise sizing. Potential enhancements include adjusting bets relative to the pot, using an agent, or applying external functions based on simple rules.
-
Data Quality: The model was trained on data from a single professional player, representing 8 million tokens. More quality hands could provide a broader range of game configurations.
-
Evaluation: Assessing a poker player’s level is challenging, as there is no easily calculated ELO score. Furthermore, there are few metrics for evaluating post-flop play. Additional testing across multiple online games would be beneficial.
While MistralBluff has demonstrated promising capabilities, addressing these aspects could significantly enhance its performance.